西元 1990 年,美國NIH推出人類基因體計畫(The Human Genome Project (HGP)),隨後,英國、日本、法國、德國、中國和印度共 20 個研究單位先後加入,終於在 2001 年提出人類基因體草稿初稿並同時發表在 Nature [1]和 Science [2]上(如圖一所示),並在 2003 年成功完成此草稿(Working draft),以此加速推動人類健康和疾病治療研究進展。

問題是:
奇怪?不是西元 2003 年人類基因體就己經完成解密了,怎麼標題卻說現在精準基因體的時代才到來呢?
其實,這 20 年來,所謂的人類參考基因體 (Human Reference Genome) 一直都是處於不完整的狀態(如圖二所示),雖然科學家們一直努力修正錯誤及彌補缺少的部分,可以由上星期發表在 Nature 的文章[3]中得到人類參考基因體總長度的演進,之前由 the Genome Reference Consortium (GRC) 在 2009年推出的 GRCh37 到 2013年推出最新版本的 GRCh38 約多了快 1 Mbps (最新的補丁是 2019 年推出的GRCh38.p13),但仍約有 5 % 是所謂的 gapped regions,也就是科學家們使用當時最新的定序技術並無法知道那些 DNA 區段到底是 A/C/G/T 那一種鹼基對組成,這些 Gap 大多落在 Telomere 或 Centromere 區域。

雖然相關定序技術持續演進,但這個問題一直困擾著科學家們,所以 NIH 的 Adam Phillippy 和 UCSC 的 Karen Miga 一起主持的 Telomere-2-Telomere (T2T) Consortium [4] 的目標就是希望能組出一個完整的人類基因體,並把每條染色體從頭到尾完整地解析出來。我從前年就一直密切地關注該組織的進展,因為這對精準醫療是非常重要的資料(甚至可以說是資產)。
去年 T2T Consortium 發表由 T2T-CHM13 試著完整組出 Chromosome X [10],今年二月推出 v1.0 版 [5],但這時有 5 個染色體仍不完整,但在上星期推出的 v1.1 版發表在 BioRxiv 上的文章 [6] 就是所謂 Gapless 的完整版終於震憾登場了。論文中提到其非凡的成就:
多到找近 200 Mbps 的新序列,包含 2千多個 Paralogous Gene Copies,其中有 1百多個可能是 Protein Coding Genes.
看到這邊,可能有些讀者仍一頭霧水,這不就只是把人類參考基因體缺少的那些區域補上去而己嗎?有什麼好大驚小怪的。因此,我試著用以下四部曲來深入探討這個題議與未來發展。
第一部 :困獸之鬥
不完整的參考基因體會導致什麼問題呢?
以時下最熱門的人工智慧相關應用來說,影像辨識是目前最成功的應用了。例如,我們打算開發出一個十二生肖影像辨識系統,所以第一步先收集十二生肖的所有影像資料來訓練出一個 AI 預測模型;第二步再拿待辨識的動物圖片餵給AI預測模型進行預測;第三步 AI 模型會吐出預測結果。

但「不完整的參考基因體」造成的問題就如同圖二所示,在第一步訓練資料集中少了老鼠的影像與類別標註所訓練出的 AI 模型;當第二步拿老鼠的圖片來進行預測;第三步,這時超強的 AI 預測模型根據尾巴的相似性,預測出是雞的機率有80%,是蛇的機率有 75%。這時,不管模型再怎麼調優,也不會得到正確答案的,因為「老鼠」打從一開始訓練集中就從沒被標示到。
𧗠生的問題不僅於此,大家還會根據預測的結果進行後續的分析與研究,如預測成「雞」之後,科學家們漸漸發現有「雞開始長出門牙了」;若預測成「蛇」之後,科學家們發現「蛇也長出腳了」,馬上就進行「畫蛇添足」的論文發表。然而真正「老鼠」這個物種則一直處在妾身未明的灰色地帶,造成科學家們慢慢覺得怎麼「雞」和「蛇」的後續相關研究分析結果越來越奇怪、越來越多例外,同時也發表更多的論文(i.e. 蛇長出耳朵、雞變胎生、蛇會分泌乳汁餵食下一代、、、)。直到有一天,某位科學家終於發現「老鼠」這個物種的存在,把它加到訓練資料集後重新進行訓練,之後,世界終於恢復平靜。
同樣的,「不完整的參考基因體」會造成相同的問題,若使用次世代定序(Next-Generation Sequencing)的全基因體定序(Whole Genome Sequencing )時,原本參考基因體缺失的區域(Gap Regions)上的序列資料在 Read Mapping 進行回貼時,處境就如同老鼠的尾巴一樣,這些 reads 被貼到其它基因的位置,導致 Variant Calling 時會誤認為這些基因產生變異。因為這是系統性的問題,所以當科學家收集一群有相同疾病的病患定序資料時,很容易觀察到這些假變異 (False Positives),進而做出錯的基因與疾病的相關性連結,更會造成以此來進行藥物開發的失敗率提高,導致藥廠覺得基因資料對藥物開發沒什麼幫助;同樣的,醫生也會覺得根據基因變異的資訊來進行治療也沒多大用處,導致精準醫療在基因體這領域上的進展一直很緩慢。
第二部:破繭而出
上星期 T2T Consortium 終於推出的 Gapless Human Reference Genome,命名為 T2T-CHM13 v1.1 版, 並發表在 BioRxiv 上[6] 。在論文中,特別與前一版參考基因體 GRCh38 來做比較,可以發現 T2T-CHM13 v1.1 比 GRCh38p13 多了 122 Mbps 的長度,還有最重要的是 Gap bases 為 0。同時,基因數量也從 60,090 增加到 63,494 個,主要增加的區域大部分是 repeated region,所以相對的 repeats 的比例也從 50% 增加到 53.9%。

大家一定會好奇為什麼 T2T Consortium 可以解決這個困擾大家近二十年的問題,該組織的確花了很多經費與心力來完成,有興趣的人可以閱讀他們發表的文章 [6] 。這裡,我試著歸納出兩點重點:
- CHM cell line 的挑選
- PacBio HiFi Read 的神救援
以下就分別為大家深入探討:
CHM
為什麼 T2T Consortium 要將最新版的 Reference Genome 拿CHM 縮寫來命名呢?原因就是因為他們拿「Complete Hydatidiform Mole (CHM) cell line」來進行定序(如圖三所示)。這個 Cell Line 有什麼特別的呢?中文為「完全性葡萄胎」[8],一般為雙套染色體46XX,特徵有:絨毛呈廣泛性水腫、絨毛外之滋養層細胞增生、絨毛中之血管消失和無胎兒及胚胎組織。一般細胞會有兩套染色體,一套來自爸爸,一套來自媽媽。而 CHM 細胞株是完全沒有母系的染色體,兩套全來自父系染色體的 46 XX。所以"比較"沒有 Heterozygous Variants 的干擾,相對來說在進行基因體組裝的難度就可以大大減少。
PacBio HiFi Read 的神救援
過去 6 年,T2T Consortium 嘗試使用 120× Oxford Nanopore ultra-long read sequencing (ONT)、100× Illumina PCR-Free sequencing (ILMN)、 70× Illumina / Arima Genomics Hi-C (Hi-C)、BioNano optical maps 和Strand-seq 來進行組裝。如去年發表的 Chromosome X [10] 是基於 ONT 當 backbone 進行組裝,其 error rate 仍偏高,高難度的組裝使得專案進度緩慢。後來改用30× PacBio circular consensus sequencing (HiFi) reads 當 backbone,因為其 error rate 大大下降,再配合開發出合適的演算法(i.e. HiCanu [14])進行分析,所以讓基因體組裝變簡單而加速這個專案的進展,如下圖就是其組裝時的 String Graph :
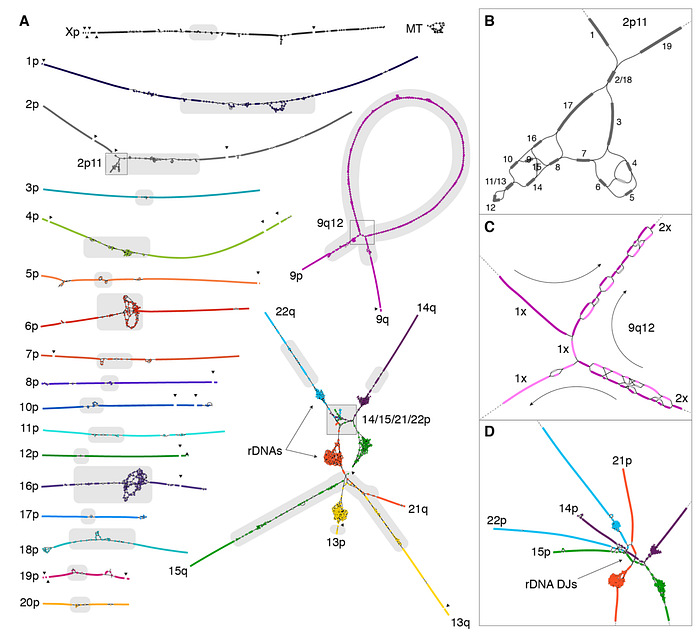
因此,T2T-CHM13 v1.1 可以被完全解析出來,這次重大突破主要是在五條 Acrocentric Chromosomes的 p-arm 區域,如同圖三中可以清楚看到第 13, 14, 15, 21 和 22 號染色體它們的著絲點是明顯偏向 p-arm 這一邊的。之前因為臨近 Centromere 而難以處理,這次被完全解密後可以從下圖清楚看出其結構:
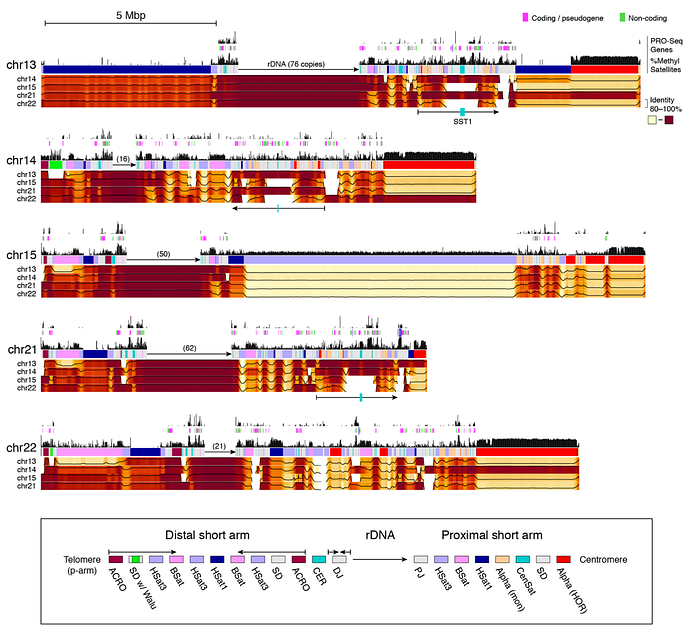
第三部:以終為始
介紹到這邊,大家是不是認為 T2T Consortium 的階段性目標己經完成了呢?眼尖的讀者應該到 CHM13 Cell Line 的限制,就是它沒有「Y 染色體」,所以目前 T2T-CHM13 v1.1 是沒有 chrY 的參考序列。那該怎麼辦呢?該組織打算拿 HG002 的 Y 染色體來進行組裝,應該不久的將來就會釋出。
另外,每個人的基因體是獨特的,而目前 T2T Consortium 僅是以一個 cell line 做出來的參考基因體,並不能代表所有人種。所以該組織提出「The Human Pangenome」的目標,強調在精準醫療之路對人種的差異的重要性,而 CHM13 只是一切的開始,群體性的參考基因體才是最終的目標,有興趣的人可以觀看以下這部影片介紹:
然而,可以想像不久的將來,我們即將面臨 Pan-Reference Genome,屆時基因體分析工具的複雜度(i.e. Graph Genome [15])與計算資源的需求都會大大提升,這也是我們身為生資人員可以好好發揮的重要舞台。
第四部:任重而道遠
看到這邊,大家是不是準備要衝了呢?先等等,容我再補充一些資料給大家參考參考:
動搖國本的參考基因體版本更新
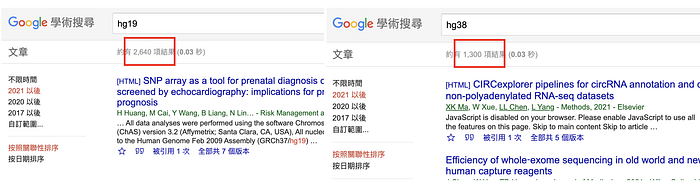
前一版參考基因體 GRCh38 早在 2013 年就公佈了,但到目前為止,今年近七成的醫學論文發表還是基於 2008 年的 GRCh37(如圖六所示), 同時很多基因檢測廠商的報告也還是基於 GRCh37 的參考基因體。這時,大家心想不是就換參考基因體的檔案就好了嗎?跑相同的分析流程,就可以得到新的結果了,應該沒有什麼困難的。事實上,參考基因體版本更新會牽扯到另外兩個問題:「相關資料庫的升版」和「分析流程撰寫的架構設計」
關於第一個「相關資料庫的升版」的問題,在二級分析的流程中,只需要把 Reference 換掉即可一路跑到變異點資訊的 VCF 檔案,除非是 Targeted Panel 需要再另外準備對應的 BED 檔案。所以版本更新主要的困難點是後續的三級分析,包含 Annotation Databases 和 black/white list 等跟 Chromosome coordination 有關的資料。
有些人可能會說直接使用 LiftOver [11]這類工具即可,這作法的確很方便,但這種作法其實己經失去版本更新的初衷,如同十二生肖「老鼠」的問題還是一樣存在。
但若第一個問題己經被順利解決的情況下,是不是就可以輕輕鬆鬆升級了呢?答案當然是 「Yes」,只必須基於一個大前提:「分析流程的撰寫是有設計過的」。沒設計過的程式是無法順利更新參考基因體版本的,因為這一更動可是會動搖國本的,相對應資料庫和設定檔是否散落在分析流程各處,必須要有熟這個分析流程的人才知道要去那裡改。但時間久遠,不是當初設計者己經忘了或早己離職,或者早年開發分析流程時根本沒把參考基因體的更新放到軟體需求中,所以才會如此窒礙難行。但若資料存放位置有設計過,相關分析流程有設計過,相信只要資料放好,改個參數就行了。
生態系的形成
上述的第二個問題只要有相關軟體工程背景或有大型軟體系統開發經驗的人應該都可以順利解決,所以實際上只剩第一個問題,需要整個生態系提供更新版的資料庫和相對應的工具才行。以作者多年來觀察各方需求,列出以下四個指標性資料庫和工具:
截止目前為止 (2021/06/21),以上四個指標性的資料庫和工具尚未整合 CHM13 v1.1 的版本,所以建議大家不需要急著換成這個版本。
根據T2T Consortium 發表在 BioRxiv 的論文,雖然主要是說明 T2T-CHM13 v1.1 版本的狀況,但在論文中提供 UCSC Genome Browser 的網站連結卻是用 v1.0 的版本。所以試著 Hack 一下它,就可以調出 v1.1 目前的進度,如下圖所示:

這領域進展很快,所以建議大家先讓自己準備好,等精準基因體的浪潮來臨時,就可以乘風破浪,快速推進。
心得分享

以上是我這次想跟大家分享的內容,本想在此停筆。但心中突然冒出美國作家 Lisa McMann 的這句話(如圖八),T2T-CHM13 v1.1 的確是這二十年來的重大進展,但這只是剛開始,還有更多好玩的事物值得大家繼續投入心力研究。
要實現「精準醫療」的前提是必須要先達到「精準基因檢測」;
要達到「精準基因檢測」的前提就必須要先有「精準參考基因體」。
隨著 T2T Consortium 發表 T2T-CHM13 v1.1 版本及之後的 The Human Pangenome,相信「精準參考基因體」在不久的將來即將實現,隨之而來的是「精準基因檢測」的推進,讓我們朝向「精準醫療」的世代繼續前進。真是令人興奮的時刻,除了因 COVID-19 的三級警戒被迫待在家外。
參考資料
[1]https://www.nature.com/nature/volumes/409/issues/6822
[2]https://science.sciencemag.org/content/291/5507
[3]https://www.nature.com/articles/d41586-021-01506-w
[4]https://sites.google.com/ucsc.edu/t2tworkinggroup/home?authuser=0
[5]https://www.nature.com/articles/d42859-020-00117-1
[6]https://www.biorxiv.org/content/10.1101/2021.05.26.445798v1.full.pdf
[7]https://i2.kknews.cc/SIG=1n0i95t/nn100091948pn46pq41.jpg
[8]https://www1.cgmh.org.tw/intr/intr4/c8710/C6/Content/Content4/C6_4_23.htm
[9]https://lh3.googleusercontent.com/Z5580R2dzGJa6oHat0TC5xq3SW6d3P9hh5GFj_f8wfW-jIzNZ6pbi1pLWQMCfYmr9Sri3oOcLQieYZJEYGh41dCrRqbzClYs81o7ELLndAomMgWD=w1280
[10]https://www.nature.com/articles/s41586-020-2547-7
[11]https://genome.ucsc.edu/cgi-bin/hgLiftOver
[12]http://genome.ucsc.edu/cgi-bin/hgTracks?db=hub_2395475_t2t-chm13-v1.1&lastVirtModeType=default&lastVirtModeExtraState=&virtModeType=default&virtMode=0&nonVirtPosition=&position=chr17%3A43266285%2D44605284&hgsid=1123883565_RrS231qVRKlCqzhgOLaaoNm1zJra
[13]https://www.azquotes.com/author/17842-Lisa_McMann
[14]https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7545148/
[15]https://www.sevenbridges.com/category/graph-genome/
